1. Graphical User Interface#
1.1. Introduction#
For the tutorial, we will use flow cytometry files coming from a growth experiment with two gut bacterial species, Roseburia intestinalis (RI) and Bacteroides thetaiotaomicron (BT). These two species were grown in mono- and co-culture for up to 120 hours, as shown below:
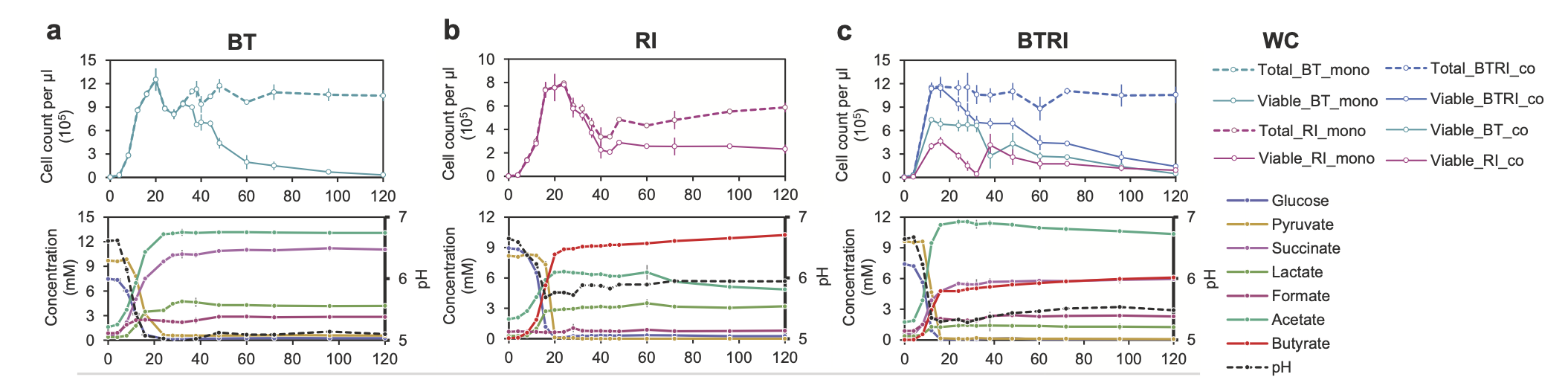
In this experiment, dead/live staining with propidium iodide and SYBR-Green was applied. Propidium iodide is a stain that enters cells with broken membranes, which we therefore count as dead. SYBR-Green is a DNA-binding molecule that helps distinguish cells from background particles that do not contain DNA. Thus, viable cells should stain green and not red.
If you are interested in the biological background of the experiment, please check out the article.
The flow cytometry data for the growth curves shown above are available at flowrepository.org. We are going to work here only with one time point (50 hours). You can find the files used in the tutorial here.
When you open CellScanner, you see the graphical user interface (GUI) shown below. Please be patient, opening the GUI can sometimes take a minute.
1.2. Import Data#
The first step is to import the data. You can do this by clicking on “Import Data”. When you click the Select blank file button, you can navigate to the corresponding fcs files. When you click the Add Species button, a new button appears next to a text field that allows you to assign the name to the fcs files belonging to the same species. Note that you can select several files at once for both blank and mono-culture files! Optionally, you can also specify an output directory where results will be saved. If you do not specify one, results will go in an output folder created on the fly inside the CellScanner directory. If you previously trained a model for your data, you can also re-use it. Here, we work with two blank files and three biological replicates for each monoculture, with the samples collected at 50 hours.
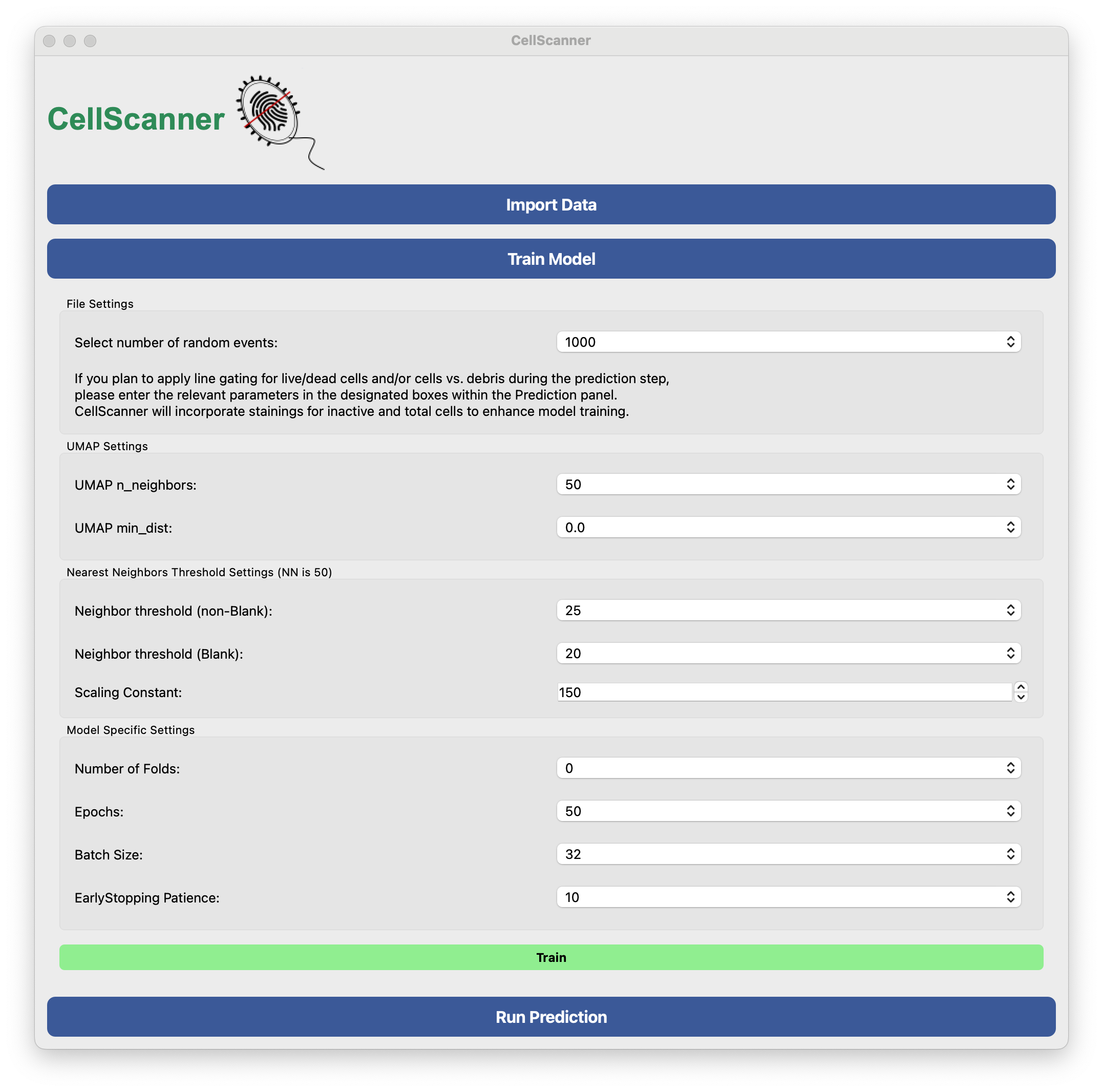
1.3. Train Model#
Next, we open the Train Model panel. If the CellScanner window becomes too big for your screen, close the Import Data panel. Here, we are going to use default values as shown below. UMAP is run first to remove debris. Essentially, this is done by clustering events from blanks and monocultures and then removing events from monocultures that are too similar to events in blanks. Next, a model (here a neural network) is trained on the filtered monocultures.
Optionally, you can apply gating to the mono-cultures. If you wish to do so, please open the Run prediction panel and click the Apply line gating checkbox. In this example, samples were treated with SYBR Green and propidium iodide. The latter is not membrane-permeable and is a red flurescent stain. Thus, it can enter cells only if their membrane is ruptured and cells stained red are therefore treated as dead. In contrast, SYBR Green is a membrane-permeable green fluorescent stain that binds to DNA. Thus, any event that is not green does not contain DNA and should better not be counted as a cell. The thresholds have to be specified as a function of the intensity values for the corresponding channels in mono- and cocultures. Usually, the software accompanying your flow cytometer can visualise intensities in different channels as histograms and scatter plots, thereby helping you to select thresholds. Here, we will set the thresholds as follows:
Staining inactive cells: FL2-H > 2000000
Staining all cells: FL1-A > 500000
Model training should be fast (within one minute).
Model performance files will be stored in a sub-folder in your specified output folder (if you did not specify one, then in the CellScanner folder).
The sub-folder name starts with working_files and ends with a time stamp.
It contains another folder called model, in which you will find a number of files encoding the trained neural network, a file called model_statistics.csv and two html files, which will open in your browser when clicked.
The first shows a UMAP projection before and the second one after filtering.
An event is filtered if its neighbors in the UMAP embedding do not have the same label (the number of neighbors considered is among CellScanner’s parameters).
The model_statistics.csv file contains information about classification performance, including accuracy, precision, recall, F1 score and the confusion matrix.
1.4. Run prediction#
We are now ready to apply the trained neural network on one or several cocultures. For this, we open the Run Prediction panel by clicking on it. As with monocultures, several coculture files can be selected and imported at once. If more than one coculture is selected, the trained neural network will be applied to each coculture in turn. Here, we are importing six replicates of the coculture (btriA-F). Optionally, the “uncertainty” thresholding can be enabled by clicking the box next to “Apply filtering on the predictions based on their uncertainty scores”. Events that cannot be easily assigned to one species have a high uncertainty (entropy). CellScanner automatically computes an uncertainty threshold that maximizes model performance. If uncertainty thresholding is enabled, events with uncertainty above this threshold will be filtered out. Note that the threshold can be manually adjusted. Next, we specify three flow cytometer channels to be used in the visualization.
We can also optionally use the line gating that we already appplied to the monocultures, which will prefilter fcs files before UMAP. In this example, FL1 and FL2 are the green and red channel, respectively, whereas H and A are height and area of the light signal. All events with FL2-H values above the threshold will be treated as dead cells and removed. All events with FL1-A values above the threshold will be counted as cells, so events below it will be removed as DNA-free debris. This implements a simple line gating as shown in the scatter plot below for one coculture. Of note, the same thresholds are applied to all mono- and cocultures and should therefore be carefully selected based on visual inspection of intensities in corresponding fcs files.
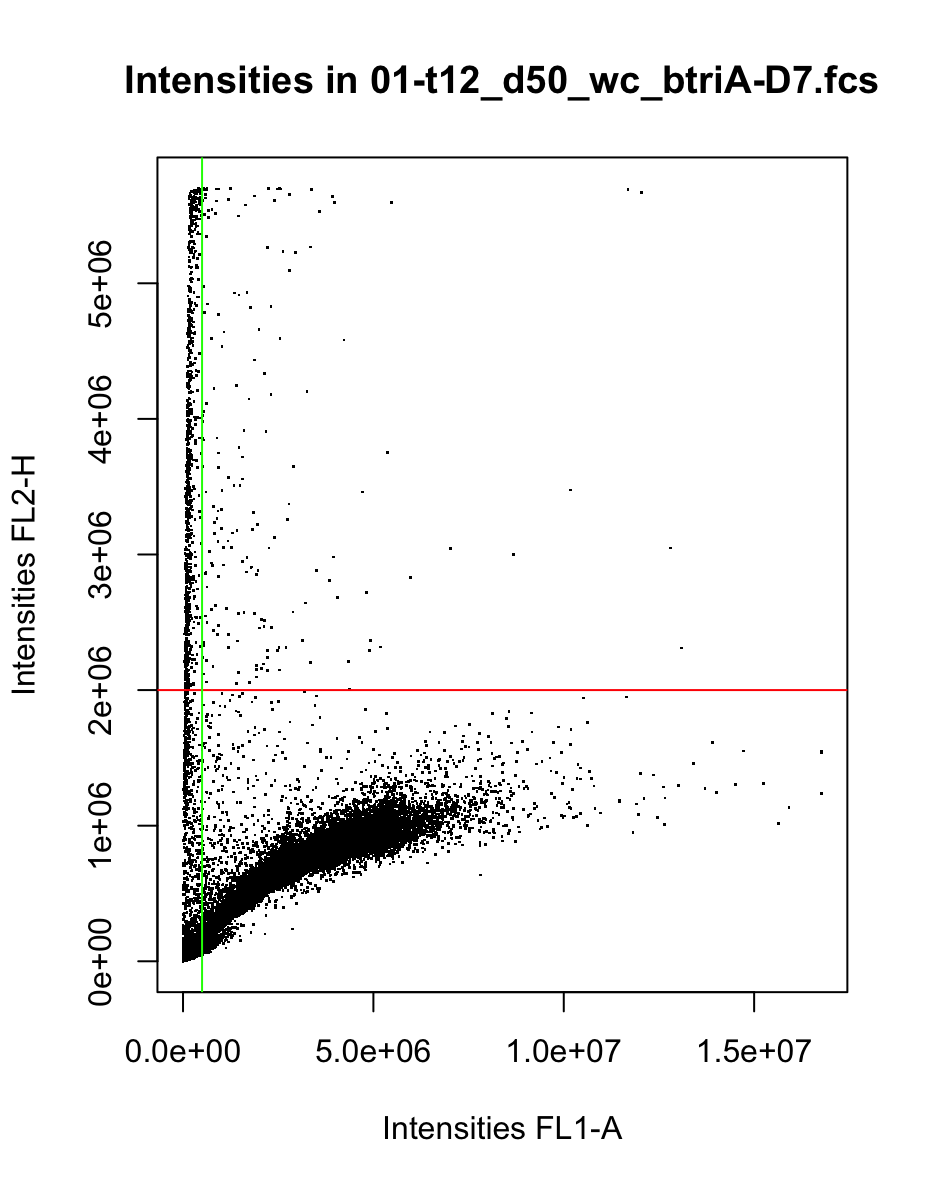
Clicking “Predict” will then launch the prediction step.
The prediction should also happen within one minute. The output is stored in a folder called “Prediction” (followed by a time stamp) that is either located in the specified output folder or the CellScanner folder. For each coculture, the following files are generated:
prediction_counts.csv, which contains the predicted counts for debris (blank), for each species, and also for the unknown events if uncertainty thresholding was enabledraw_predictions.csv, which is the fc file extended with prediction results (labels and, if enabled, uncertainties)uncertainty_counts.csv, which lists the number of uncertain events per label if uncertainty thresholding was enabled3D_coculture_predictions_species.htmlplots events in a 3D plot spanned by the three selected flow cytometer channels and colors them by species3D_coculture_predictions_uncertainty.htmlis the same with events colored by prediction uncertaintysub-folder
gatedprovides more information and a plot on gating if stains were providedsub-folder
heterogeneity_resultsquantifies and visualizes overall and species-specific heterogeneity
If more than one coculture file was provided, merged_prediction_counts.csv will list the counts for each coculture, and merged_uncertainty_counts.csv will list the number of uncertain events in each category for each coculture.
Below is the result for the six coculture replicates:
Species |
Coculure 1 |
Coculture 2 |
Coculture 3 |
Coculture 4 |
Coculture 5 |
Coculture 6 |
|---|---|---|---|---|---|---|
BT |
140116 |
158746 |
140214 |
142779 |
154802 |
144496 |
RI |
80022 |
40105 |
89645 |
75130 |
94461 |
90365 |
Blank |
664 |
705 |
677 |
594 |
817 |
687 |
Unknown |
29 |
39 |
38 |
45 |
246 |
127 |
At 50 hours, the coculture is dominated by Bacteroides thetaiotaomicron according to CellScanner.